
The world is overflowing with data. From every click you make online to the purchases you swipe your credit card for, data is constantly being generated. But what good is all this data if we can’t harness its power? This is where machine learning (ML) steps in.
Machine learning is a subfield of artificial intelligence (AI) that allows computers to learn without being explicitly programmed. By analyzing data, ML algorithms can identify patterns, make predictions, and even make decisions. It’s a rapidly evolving field with the potential to revolutionize the way we live and work.
This blog post serves as a foundational pillar for understanding machine learning. We’ll delve into the core concepts, explore different learning paradigms, and unveil the potential applications of ML in the business world. This knowledge will act as a springboard for you to delve deeper into specific areas of machine learning through future blog posts.
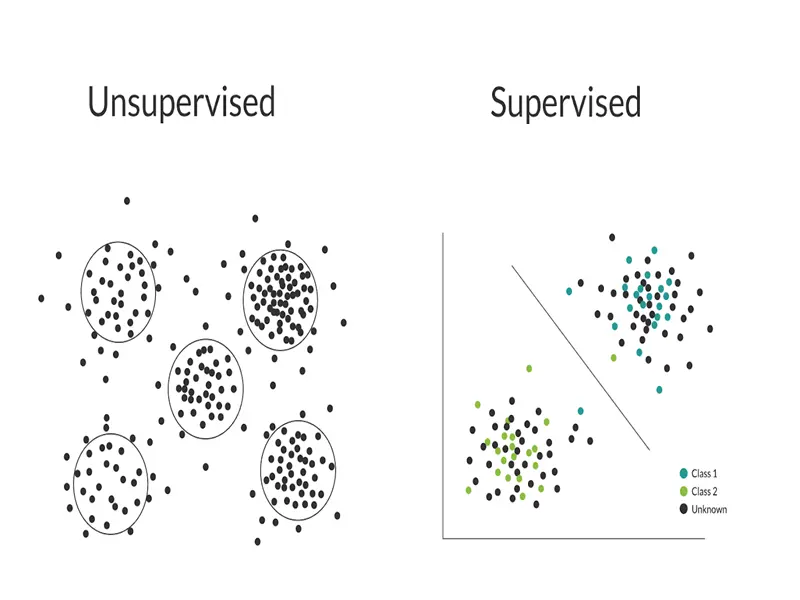
Supervised vs Unsupervised Learning
Imagine you’re a teacher showing your students pictures of animals. In supervised learning, you label each picture as a cat, dog, or bird. This labeled data is fed into an ML algorithm, which learns to identify the characteristics of each animal. Later, when shown an unlabeled picture, the algorithm can predict the animal category based on what it has learned.
This is the essence of supervised learning. It involves training an algorithm using labeled data sets. The data acts as a guide, teaching the algorithm the relationship between inputs and desired outputs. Common supervised learning tasks include:
- Classification: Categorizing data points, such as classifying emails as spam or not spam.
- Regression: Predicting continuous values, like forecasting future sales figures.
On the other hand, unsupervised learning is like letting your students explore a room full of toys and discover patterns on their own. The data is unlabeled, and the algorithm is tasked with finding hidden structures or groupings within the data. Here are some common unsupervised learning tasks:
- Clustering: Grouping similar data points together, such as grouping customers with similar buying habits.
- Dimensionality reduction: Simplifying complex data sets by identifying the most important features.
Machine Learning Algorithms Explained: Regression, Classification, Clustering
Now that you understand the two main learning paradigms, let’s explore some popular machine learning algorithms that fall under each category.
Regression Algorithms
- Linear Regression: This is the simplest regression algorithm. It finds a linear relationship between an independent variable (X) and a dependent variable (Y). For example, predicting house prices based on square footage.
- Decision Trees: These algorithms create a tree-like structure with branching conditions based on features of the data. They are effective for making predictions on a variety of data types.
- Support Vector Machines (SVMs): SVMs aim to create a clear separation line (hyperplane) between different categories in the data. They excel in high-dimensional spaces and are often used for image classification.
Classification Algorithms
- Logistic Regression: A specialized form of regression used for binary classification problems (two categories). It predicts the probability of an event belonging to a specific class.
- K-Nearest Neighbors (KNN): This algorithm classifies data points based on the majority vote of their nearest neighbors in the training data.
- Naive Bayes: This probabilistic classifier assumes independence between features. It’s efficient for large data sets and text classification.
Clustering Algorithms
- K-Means Clustering: This is a simple yet effective clustering algorithm. It partitions data points into a predefined number (k) of clusters based on their similarity.
- Hierarchical clustering: This method creates a hierarchy of clusters, allowing for a more granular exploration of the data’s structure.
- Density-Based Spatial Clustering of Applications with Noise (DBSCAN): This algorithm identifies clusters of high data density and can handle outliers effectively.
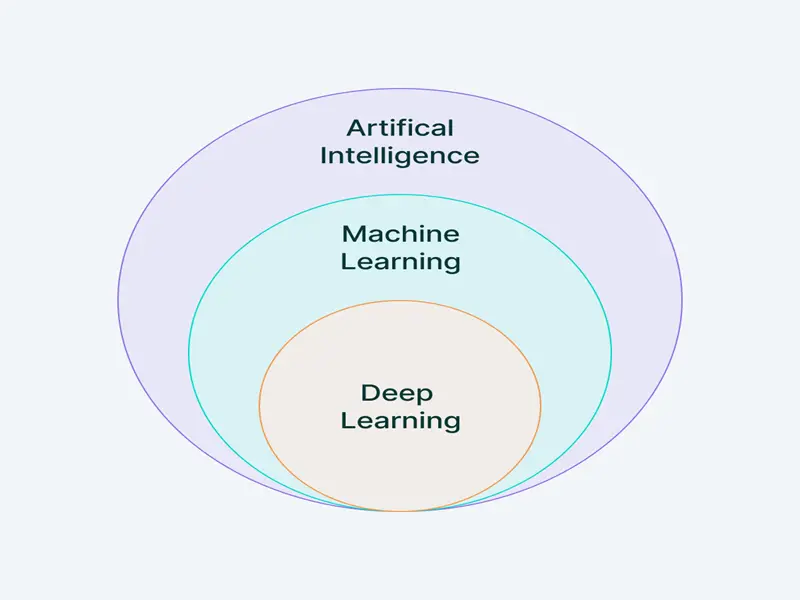
Introduction to Deep Learning
Deep learning is a subfield of machine learning that utilizes artificial neural networks with multiple hidden layers. These complex networks are inspired by the structure and function of the human brain. By processing data through multiple layers, deep learning models can learn intricate patterns and achieve high levels of accuracy in tasks like:
- Image recognition: Identifying objects and scenes in images with exceptional precision.
- Natural Language Processing (NLP): Understanding and manipulating human language for tasks like machine translation and sentiment analysis.
- Speech recognition: Converting spoken language into text with remarkable accuracy.
Deep learning has become a game-changer in various fields, but it requires significant computational resources and large amounts of data for training.
Training and Evaluating Machine Learning Models
The journey of an ML model doesn’t end with choosing an algorithm. Here’s what happens after you’ve selected your weapon of choice:
- Data Preparation: This crucial step involves cleaning, pre-processing, and transforming your raw data into a format suitable for the chosen algorithm. This might involve handling missing values, scaling numerical features, and encoding categorical variables.
- Training: The prepared data is then split into two sets: training data and testing data. The training data is fed into the algorithm, which learns the underlying patterns and relationships within the data.
- Evaluation: The model’s performance is assessed using the testing data. Common metrics for evaluation include accuracy, precision, recall, and F1 score for classification tasks, and mean squared error (MSE) or R-squared for regression tasks.
Here’s a crucial point to remember: Machine learning models are not perfect. They can suffer from overfitting, which occurs when the model learns the training data too well and performs poorly on unseen data. Techniques like regularization and using a validation set can help mitigate overfitting.

Using Machine Learning in Your Business
Machine learning is no longer the sole domain of tech giants. Businesses of all sizes can leverage its power to gain a competitive edge. Here are a few examples:
- Customer Segmentation: Using customer data, businesses can group customers with similar characteristics and buying behaviors. This allows for targeted marketing campaigns and personalized product recommendations.
- Fraud Detection: ML algorithms can analyze transaction patterns to identify suspicious activity and prevent fraudulent transactions.
- Product Recommendation Systems: E-commerce platforms use ML to recommend products to users based on their past purchases and browsing history. This can significantly improve customer engagement and sales.
- Predictive Maintenance: By analyzing sensor data from equipment, businesses can predict potential failures and schedule maintenance proactively, reducing downtime and costs.
- Market Research: ML can analyze vast amounts of social media data and customer reviews to understand customer sentiment and identify emerging trends.

The Future of Machine Learning
Machine learning is a rapidly evolving field with immense potential to transform industries and improve our lives. As computational power increases and data becomes more abundant, we can expect even more sophisticated ML applications to emerge. Here are some exciting trends to watch out for:
- Explainable AI (XAI): As ML models become more complex, the need to understand their decision-making process becomes crucial. XAI techniques aim to make these models more transparent and interpretable.
- AutoML: Automating the process of selecting and tuning machine learning algorithms can make ML more accessible to businesses and individuals with limited technical expertise.
- Reinforcement Learning: This type of machine learning involves an agent interacting with an environment and learning through trial and error. It has promising applications in areas like robotics and autonomous systems.
By understanding the fundamental concepts of machine learning and staying informed about emerging trends, you can position yourself to leverage this powerful technology and unlock its potential for your business and your future.



